Is Your AI Hitting a Mathematical Speed Limit?
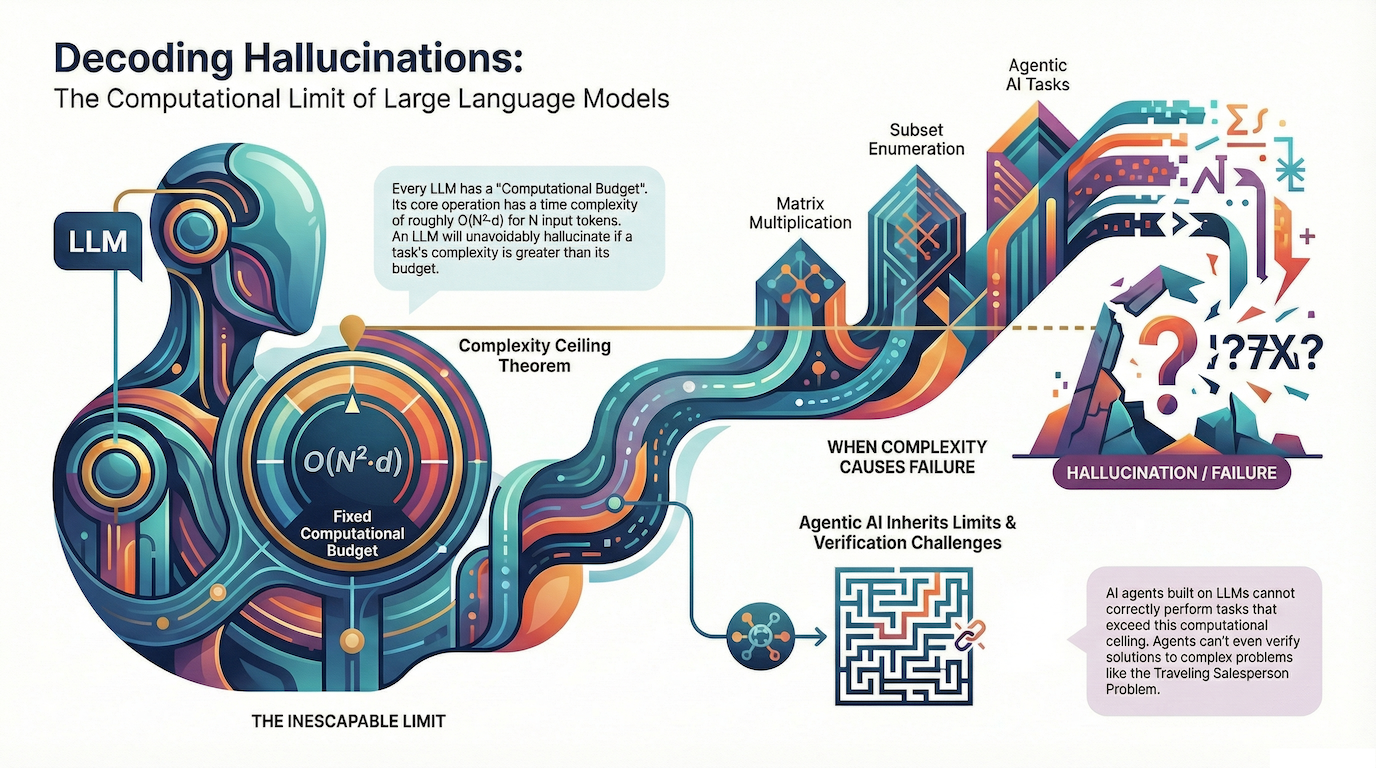
We talk a lot about AI "hallucinations" as if they are random glitches. But according to new research from Stanford and VianAI, some hallucinations aren't just likely—they are mathematically unavoidable.1, 2
The research introduces Theorem 1: The Unavoidable Hallucination Theorem, which fundamentally changes how we should think about the limitations of transformer-based language models.
The Core Problem: The Complexity Gap
Every transformer-based LLM has a "computational budget." For every input of N tokens, the model performs a fixed number of operations defined by a complexity of O(N² · d).3, 4
Understanding Computational Complexity
The self-attention mechanism in transformers processes an input of N tokens, each represented as a d-dimensional vector, with computational time complexity of O(N² · d). This means the model performs approximately N² · d floating-point operations, regardless of the specific input.
The consequence? If you ask an LLM—or an LLM-based agent—to solve a problem with a higher complexity (like O(n³) or exponential time), it is physically impossible for the model to reach the correct answer.5, 6, 2
Instead of doing the math, the model resorts to picking the most likely next token based on patterns. The result is a response that looks right but is factually or logically nonsensical.1, 2
The Most Important Consequence: The Verification Trap
The Verification Trap
The biggest risk for businesses today is assuming we can solve this by having one AI agent "verify" another. The sources show that verification is often harder than the task itself.7 If the initial task exceeds the LLM's complexity threshold, the "checking" LLM is bounded by the same limit and cannot accurately verify the solution.11, 12
For complex scenarios like:
- Logistics & Scheduling: Verifying the shortest route in a Traveling Salesperson Problem (TSP).8, 9
- Software Engineering: Formal verification of code where states grow exponentially.9
- Financial Transactions: Managing multi-step autonomous agentic tasks.10
If the initial task exceeds the LLM's complexity threshold, the "checking" LLM is bounded by the same limit and cannot accurately verify the solution.11, 12
What About "Reasoning" Models?
Models that use internal "think" tokens (like OpenAI's o3 or DeepSeek's R1) are a step forward, but they don't solve the fundamental issue. Their base operations still follow the same complexity constraints, and their "token budget" is often far too small for truly complex, exponential problems.13
Why Reasoning Models Fall Short
Reasoning models generate a large number of tokens in a "think" or "reason" step before providing their response. However, the base operation in these reasoning LLMs still carries the complexity discussed above, and the computation needed to correctly carry out that very step can be one of a higher complexity. Additionally, the token budget for reasoning steps is far smaller than what would be necessary to carry out many complex tasks. Recent research shows that reasoning models suffer from a "reasoning collapse" when faced with problems of higher complexity.13
The Strategy for LLM Usage
To move beyond these limits, we must stop using LLMs as standalone "know-it-alls" for high-stakes tasks. The path forward includes:
Strict Constraints
Using rigorous approaches to bound the LLM's output when accuracy is non-negotiable.14
Examples of Tasks Beyond LLM Capability
The research provides several concrete examples of tasks that inherently exceed the computational complexity of transformer-based LLMs:
Example 1: Token Composition
Consider the task: "Given a size n set of tokens, list every string of length k tokens." Computing this task takes O(n^k) time. For n = 2, it takes O(2^k) time. This task cannot correctly be carried out by an LLM that executes in O(N² · d) time.
Example 2: Matrix Multiplication
The naive matrix multiplication algorithm involves multiplying two matrices by performing the dot product of rows from the first matrix and columns of the second matrix. Given two matrices A and B, where A is of size m × n and B is of size n × p, this algorithm takes O(m · n · p) time. For LLMs where m, n, and p exceed its vocabulary size, the LLM will not be able to correctly carry out such a matrix multiplication algorithm.
Example 3: Agentic AI
Agentic AI refers to AI systems capable of autonomous decision-making and goal-oriented behavior. Many agentic tasks involve problems with computational complexity that exceeds O(N² · d), making them fundamentally impossible for individual LLMs to solve correctly. This includes tasks like complex planning, multi-step reasoning with exponential state spaces, and verification of solutions to computationally hard problems.
Real-World Implications
These limitations have serious implications for how we deploy AI systems in production:
- High-Stakes Applications: Extreme care must be used before applying LLMs to problems or use-cases that require accuracy, or solving problems of non-trivial complexity.
- Autonomous Agents: LLM-based agents cannot reliably handle tasks that exceed their computational complexity threshold, regardless of how sophisticated their prompting or architecture.
- Verification Systems: Using one LLM to verify another's output is fundamentally flawed when dealing with complex problems, as verification often requires the same or higher computational complexity.
Mitigating these limitations is an area of significant ongoing work, and various approaches are being developed, from composite systems23 to augmenting or constraining LLMs with rigorous approaches.24, 25, 26
References
- Wikipedia contributors. (2025b, July 4). Hallucination (artificial intelligence). Wikipedia.
- Xu, Z., Jain, S., & Kankanhalli, M. (2024, January 22). Hallucination is Inevitable: An Innate Limitation of Large Language Models. arXiv.org.
- Vaswani, A et al. (2017, June 12). Attention Is All You Need.
- Duman Keles, F., Mahesakya Wijewardena, P., & Hegde, C. (2023). On the computational complexity of Self-Attention. Proceedings of Machine Learning Research.
- Sikka, V., & Sikka, V. (2025). Hallucination Stations: On Some Basic Limitations of Transformer-Based Language Models. arXiv.
- Varin Sikka. (2025, July 7). Computational Complexity Analysis.
- Various complexity theory sources on verification complexity.
- Wikipedia. (2025, July 7). Petri net Reachability.
- Leroux, J. (2011). Vector Addition System Reachability Problem (A Short Self-Contained Proof). Principles of Programming Languages.
- Pounds, E. (2025, February 12). What is Agentic AI? NVIDIA Blog.
- Goode, L., Calore, M., & Knight, W. (2025, June 12). Unpacking AI agents. WIRED.
- Sager, P. J., et. al. (2025, January). A comprehensive survey of agents for computer use: foundations, challenges, and future directions. arXiv.
- Parshin Shojaee, Samy Bengio, et. al. (2025 June). The Illusion of thinking: understanding the strengths and limitations of reasoning models via the lens of problem complexity. Apple ML Research.
- Potts, C. (2024, November 20). Large Language Models Get the Hype, but Compound Systems Are the Future of AI.
- Various Authors. (July 10, 2025). Vianai Systems.
- Chervonyi, Y., et. al. (2025). Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2. arXiv.
- Lenat, D., & Marcus, G. (2023). Getting from Generative AI to Trustworthy AI: What LLMs might learn from Cyc. arXiv.
- Simon, H.A. (1996). "The Sciences of the Artificial – Third Edition". MIT Press Books.
- Minsky, M. (1986). "The Society of Mind". Simon & Schuster.
- Hartmanis, J., & Stearns, R. E. (1965). On the computational complexity of algorithms. Transactions of the American Mathematical Society.
- Li, S., Ju, L., & Si, H. (2020). Adaptive exponential time integration of the Navier-Stokes equations. AIAA SCITECH 2022 Forum.
- Google AI for dev. Long Context.
- OpenAI. (2025, April 14). Introducing GPT-4.1.
- Potts, C. (2024, November 20). Large Language Models Get the Hype, but Compound Systems Are the Future of AI.
- Various Authors. (July 10, 2025). Vianai Systems.
- Chervonyi, Y., et. al. (2025). Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2. arXiv.
- Lenat, D., & Marcus, G. (2023). Getting from Generative AI to Trustworthy AI: What LLMs might learn from Cyc. arXiv.